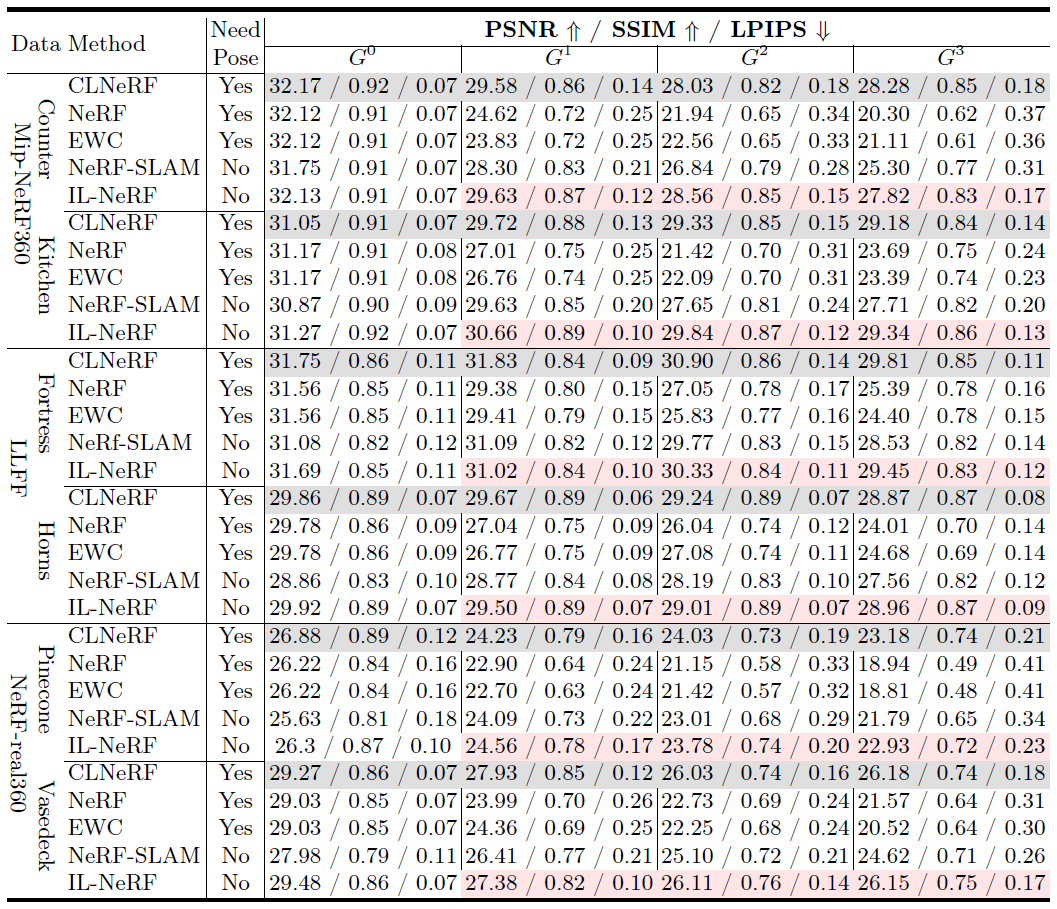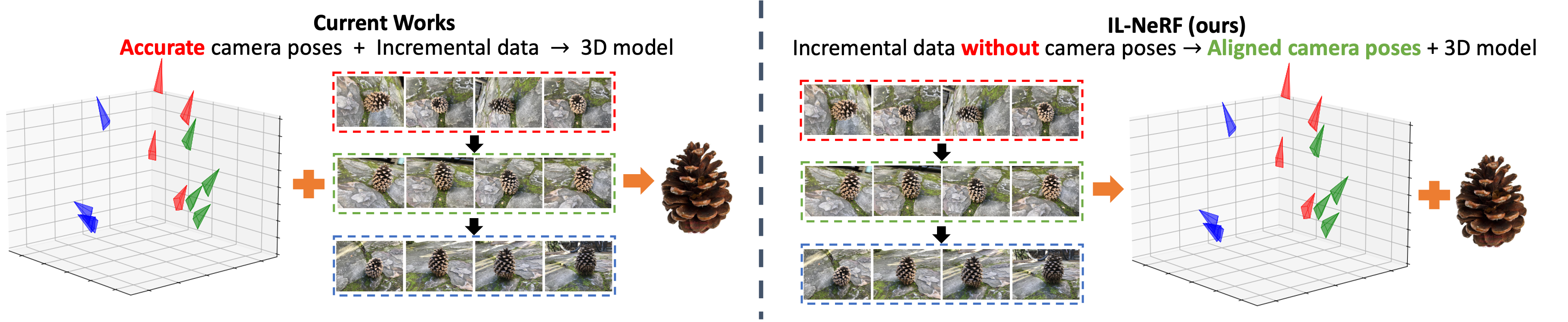
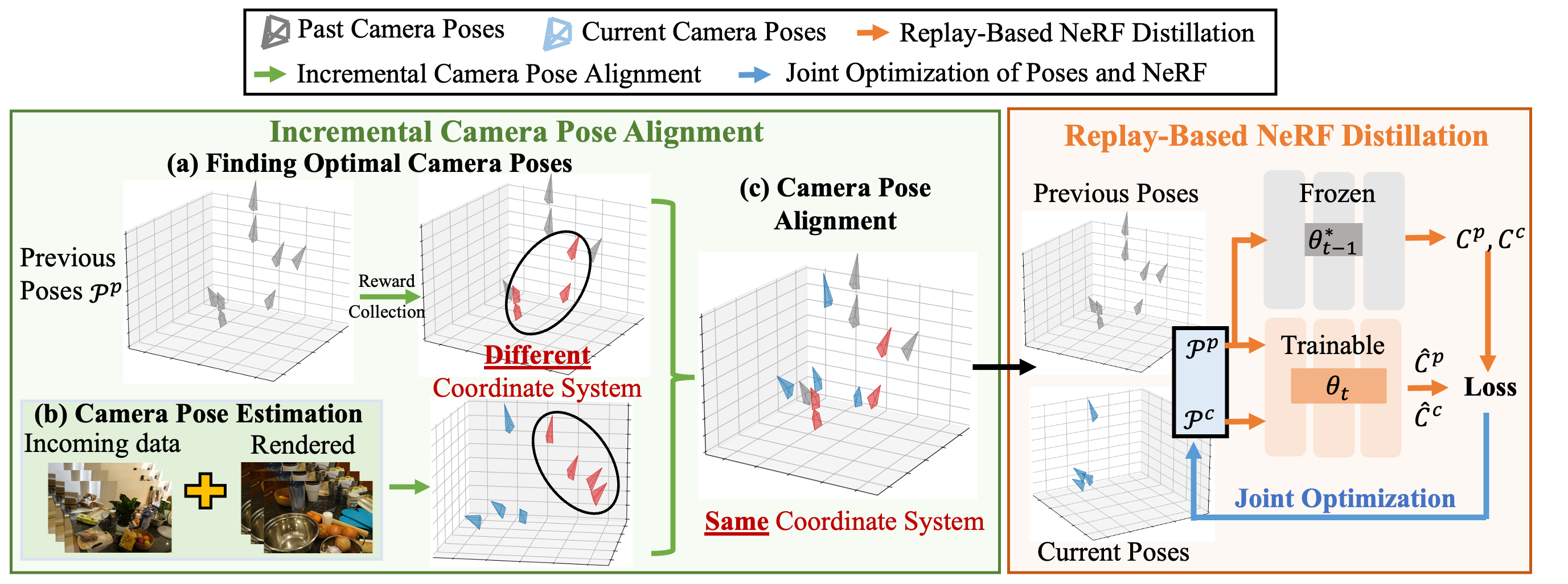
Qualitative Comparison
The original NeRF demonstrates severe catastrophic forgetting, leading to the loss of early-task scene information.
In contrast, IL-NeRF is able to preserve the scene of interest throughout the training process.

(a) Kitchen and Garden scenes in the Mip-NeRF360 dataset.

(b) Fortress and Horns scenes in the LLFF dataset.

(c) Pinecone and Vasedeskin scenes in the NeRF-real360 dataset.